
前几天看到若志 • 随笔 发布了一篇关于朋友圈rss 订阅的文章,觉得蛮有意思的,不过当时并没有要做这个东西的想法。
但是,但是,但是,后来发现大家都开始弄这个了,例如, 呆哥、夕格 (都是哥?)。这就瞬间不淡定了啊,为什么都弄了这么东西呢。写个播客而已啊,干嘛要这么卷呢,☹️,哼唧唧。
既然大家都做了,那就也弄一个呗,也算是给这个没啥人气的博客圈子带点流量。
还是参考https://www.rz.sb/archives/228/,这篇文章搞得,前面的步骤就不多写了。照着他的步骤抄就完了。
1. 安装 freshrss ,我安装的 freshrss,使用maridb 10.11.2-1303,是可以安装成功的。如果使用 mysql 失败,可以尝试高版本或者试试 mariadb 。
2.抄代码:
<?php
/**
* 获取最新订阅文章并生成JSON文件
*/
function getAllSubscribedArticlesAndSaveToJson($user, $password)
{
$apiUrl = 'https://你部署FreshRSS的域名/api/greader.php';
$loginUrl = $apiUrl . '/accounts/ClientLogin?Email=' . urlencode($user) . '&Passwd=' . urlencode($password);
$loginResponse = curlRequest($loginUrl);
if (strpos($loginResponse, 'Auth=') !== false) {
$authToken = substr($loginResponse, strpos($loginResponse, 'Auth=') + 5);
$articlesUrl = $apiUrl . '/reader/api/0/stream/contents/reading-list?&n=1000';
$articlesResponse = curlRequest($articlesUrl, $authToken);
$articles = json_decode($articlesResponse, true);
if (isset($articles['items'])) {
usort($articles['items'], function ($a, $b) {
return $b['published'] - $a['published'];
});
$subscriptionsUrl = $apiUrl . '/reader/api/0/subscription/list?output=json';
$subscriptionsResponse = curlRequest($subscriptionsUrl, $authToken);
$subscriptions = json_decode($subscriptionsResponse, true);
if (isset($subscriptions['subscriptions'])) {
$subscriptionMap = array();
foreach ($subscriptions['subscriptions'] as $subscription) {
$subscriptionMap[$subscription['id']] = $subscription;
}
$formattedArticles = array();
foreach ($articles['items'] as $article) {
$desc_length = mb_strlen(strip_tags(html_entity_decode($article['summary']['content'], ENT_QUOTES, 'UTF-8')), 'UTF-8');
if ($desc_length > 20) {
$short_desc = mb_substr(strip_tags(html_entity_decode($article['summary']['content'], ENT_QUOTES, 'UTF-8')), 0, 99, 'UTF-8') . '...';
} else {
$short_desc = strip_tags(html_entity_decode($article['summary']['content'], ENT_QUOTES, 'UTF-8'));
}
$formattedArticle = array(
'site_name' => $article['origin']['title'],
'title' => $article['title'],
'link' => $article['alternate'][0]['href'],
'time' => date('Y-m-d H:i', $article['published']),
'description' => $short_desc,
);
$subscriptionId = $article['origin']['streamId'];
if (isset($subscriptionMap[$subscriptionId])) {
$subscription = $subscriptionMap[$subscriptionId];
$iconUrl = $subscription['iconUrl'];
$filename = 'https://你部署FreshRSS的域名/'.substr($iconUrl, strrpos($iconUrl, '/') + 1);
$formattedArticle['icon'] = $filename;
}
$formattedArticles[] = $formattedArticle;
}
saveToJsonFile($formattedArticles);
return $formattedArticles;
} else {
echo 'Error retrieving articles.';
}
} else {
echo 'Error retrieving articles.';
}
} else {
echo 'Login failed.';
}
return null;
}
function curlRequest($url, $authToken = null)
{
$ch = curl_init($url);
if ($authToken) {
$headers = array(
'Authorization: GoogleLogin auth=' . $authToken,
);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
}
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
return $response;
}
/**
* 将数据保存到JSON文件中
*/
function saveToJsonFile($data)
{
$json = json_encode($data, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents('output.json', $json);
echo '数据已保存到JSON文件中';
}
// 调用函数并提供用户名和密码
getAllSubscribedArticlesAndSaveToJson('这里是FreshRSS的用户名', '这里是第3步设置的api密码');
3.创建展示页面,我直接建了一个主题模板页面。
<?php /* Template Name: Besties */ ?>
<?php get_header(); ?>
<style>
#block-nav a.post-page-numbers, #block-nav .post-page-numbers ,#block-nav .link-pages{
font-size: 1.0em;
border: 1px solid;
padding: 5px 10px;
background: white;
color: black;
transition: 0.3s;
}
#block-nav span.post-page-numbers.current {
color: white;
background: black;
border: 1px solid black;
}
#block-nav a.post-page-numbers:hover {
background-color: black;
color: #ffffff;
}
</style>
<div class="row">
<div class="col-lg-8 col-12">
<main id="content" role="main" itemprop="mainContentOfPage" itemscope="itemscope" itemtype="http://schema.org/Blog">
<div class="container">
<?php
// 获取JSON数据
$jsonData = file_get_contents('/home/wwwroot/h4ck.org.cn/output.json');
// 将JSON数据解析为PHP数组
$articles = json_decode($jsonData, true);
// 对文章按时间排序(最新的排在前面)
usort($articles, function ($a, $b) {
return strtotime($b['time']) - strtotime($a['time']);
});
// 设置每页显示的文章数量
$itemsPerPage = 38;
// 生成文章列表
foreach (array_slice($articles, 0, $itemsPerPage) as $article) {
$articles_list ='<article id="div-comment-105873" class="comment-body" style=" padding: 10px;
margin-bottom:10px;
border: 1px solid #ccc;
border-radius: 5px;
box-shadow: 0 2px 5px rgba(0, 0, 0, 0.1); ">
<footer class="comment-meta">
<div class="comment-author vcard">
<img alt="" src="' . htmlspecialchars($article['icon']) . '" class="avatar avatar-32 photo" height="32" width="32" loading="lazy" decoding="async">
<b class="fn">
<a href="' . htmlspecialchars($article['link']) . '" target="_blank" class="url" rel="ugc">' . htmlspecialchars($article['site_name']) . '</a>
</b>
<span class="says"> 发布了:<a href="' . htmlspecialchars($article['link']) . ' " target="_blank" class="url" rel="ugc">《' . htmlspecialchars($article['title']) . '》</span>
</div>
<div class="comment-metadata">
<a href="#">
<time datetime="' . htmlspecialchars($article['time']) . '">' . htmlspecialchars($article['time']) . '</time>
</a>
</div>
</footer>
<div class="comment-content">
<p>' . htmlspecialchars($article['description']) . '
</p>
</div>
</article>';
echo $articles_list;
}
?>
</div>
</main>
</div>
<div class="col-lg-4 col-12">
<?php get_sidebar(); ?>
</div>
</div><!-- /row -->
<?php get_footer(); ?>
4.在后台新建页面,模板选择 Besties,文章内容不用写任何东西,创建页面就 ok 了。
样式自己写吧,我是实在不会写样式啊,讨厌,嘤嘤嘤。
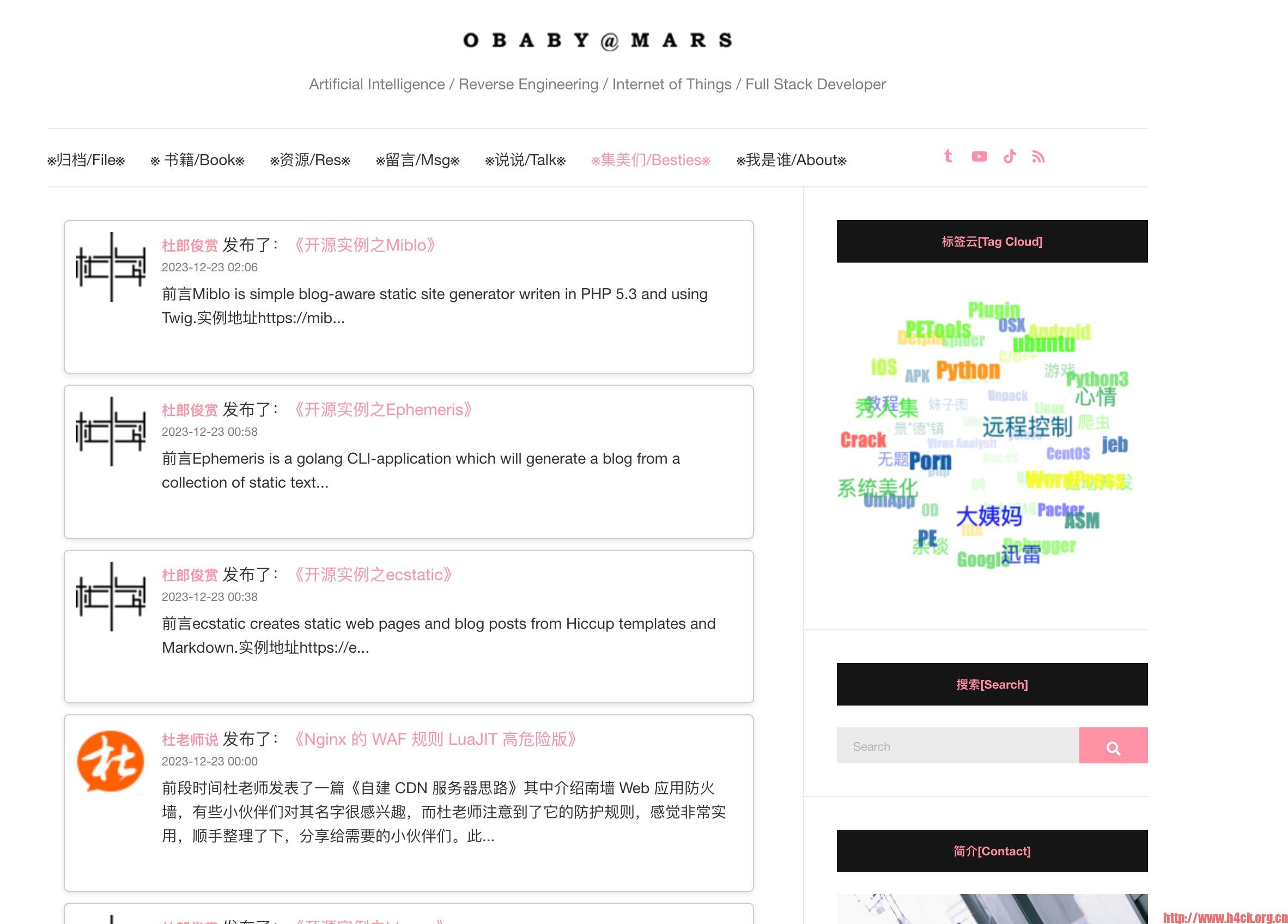
5.实际效果:
6.数据更新,我没安装任何的面板,直接通过 crontab 定时任务执行即可。
创建 freshrss.sh, 写入以下代码:
crul https://你的接口文件地址
执行 crontab -e 写入以下计划,每小时执行一次。
0 * * * * /home/obaby/sh/freshrss.sh
到这里就全部结束啦。
后话:
可能是现在 rss 不流行了?在整理订阅源的时候,好多集美们的页面上找半天都找不到rss 地址,还有一些 rss 地址是错的,至于是谁就不说啦。所以,我翻遍了友联没有rss 地址的,尝试使用/atom.xml /rss/ /feed/等默认路径依然没找到地址的,就暂时无法添加了。
下面是已经订阅的地址,集美们,如果不在里面,记得给我反馈 rss 地址啊,找的太累了。
<outline text="集美们">
<outline text="Dabenshi Blog" type="rss" xmlUrl="https://dabenshi.cn/rss.xml" htmlUrl="https://dabenshi.cn/" description="Dabenshi Blog"/>
<outline text="Echo小窝" type="rss" xmlUrl="https://www.liveout.cn/feed/" htmlUrl="https://www.liveout.cn/" description="记录着生活日常的小窝"/>
<outline text="FGHRSH 的博客" type="rss" xmlUrl="https://www.fghrsh.net/feed.php" htmlUrl="https://www.fghrsh.net/" description=""/>
<outline text="Jeffer.Z的博客" type="rss" xmlUrl="https://www.jeffer.xyz/feed" htmlUrl="https://www.jeffer.xyz/" description="在此处我嗅到人间味道"/>
<outline text="zyq.today" type="rss" xmlUrl="https://zyq.today/feed" htmlUrl="https://zyq.today/" description="那年今日-小乔的博客"/>
<outline text="东评西就" type="rss" xmlUrl="https://dongjunke.cn/atom.xml" htmlUrl="https://dongjunke.cn/" description=""/>
<outline text="九月的风" type="rss" xmlUrl="https://sep.cc/feed" htmlUrl="https://sep.cc/" description="有一些希望和理想"/>
<outline text="云晓晨CatchYun" type="rss" xmlUrl="https://blog.catchyun.com/atom.xml" htmlUrl="https://blog.catchyun.com/" description="未来路远 • 勿忘初心"/>
<outline text="博客 | 棋の小站" type="rss" xmlUrl="https://blog.qi1.zone/feed/" htmlUrl="https://blog.qi1.zone/" description="记录学习,心得,状态,生活。"/>
<outline text="安静的石头" type="rss" xmlUrl="https://www.cmdsir.com/feed" htmlUrl="https://www.cmdsir.com/" description="记录和分享生活中的点点滴滴"/>
<outline text="小小博客" type="rss" xmlUrl="https://shagain.club/feed" htmlUrl="https://shagain.club/" description="技术分享"/>
<outline text="慧行说-在知识的尽头,慢慢变老" type="rss" xmlUrl="https://liuyude.com/rss.xml" htmlUrl="https://liuyude.com/" description=""/>
<outline text="文武科技柜" type="rss" xmlUrl="https://www.wangdu.site/feed" htmlUrl="https://www.wangdu.site/" description="文武科技社的后花园"/>
<outline text="时雨の一方净土" type="rss" xmlUrl="https://noesis.love/atom.xml" htmlUrl="https://noesis.love/" description=""/>
<outline text="杜老师说" type="rss" xmlUrl="https://dusays.com/atom.xml" htmlUrl="https://dusays.com/" description="运维技术分享博客"/>
<outline text="杜郎俊赏" type="rss" xmlUrl="https://dujun.io/feed/" htmlUrl="https://dujun.io/" description="dujun.io是一个技术人的轻博客"/>
<outline text="梦之源泉" type="rss" xmlUrl="https://www.mzyq.com/feed/" htmlUrl="https://www.mzyq.com/" description="有梦才有未来"/>
<outline text="淇云博客-专注于IT技术分享" type="rss" xmlUrl="https://www.pengqi.club/feed" htmlUrl="https://www.pengqi.club/" description="又一个WordPress站点"/>
<outline text="生活文案记录分享-网站建设-seo优化-朋友圈文案-文案大全-自由笔触" type="rss" xmlUrl="https://www.cshcp.com/feed/" htmlUrl="https://www.cshcp.com/" description="自由笔触,记录分享生活中的碎碎念念,和收集到的朋友圈文案以及自己网站建设时摸索出来的一些seo优化的知识和技巧!"/>
<outline text="终成博客" type="rss" xmlUrl="https://blog.zc.wiki/rss.php" htmlUrl="https://blog.zc.wiki/" description="有情人终成眷属"/>
<outline text="绯鞠的博客" type="rss" xmlUrl="https://loli.fj.cn/atom.xml" htmlUrl="https://loli.fj.cn/" description=""/>
<outline text="美樂地" type="rss" xmlUrl="https://meledee.com/feed" htmlUrl="https://meledee.com/" description="Meledee.com"/>
<outline text="耳朵的主人 imerduo.com" type="rss" xmlUrl="https://www.imerduo.com/feed" htmlUrl="https://www.imerduo.com/" description="庆幸还有耳朵,还可以是耳朵的主人"/>
<outline text="若志 • 随笔" type="rss" xmlUrl="https://www.rz.sb/feed/" htmlUrl="https://www.rz.sb/" description="一个若志的自留地,记点想记的文章,做点想做的事."/>
<outline text="辛未羊的网络日志" type="rss" xmlUrl="https://panqiincs.me/atom.xml" htmlUrl="https://panqiincs.me/" description=""/>
<outline text="阿呆日记" type="rss" xmlUrl="https://dai.ge/feed/" htmlUrl="https://dai.ge/" description="我在人间凑数的日子"/>
</outline>

45 comments
效率很高,只是这个名点的我有点憋屈
最终不是还是给你加上了嘛,不是~~
搞垮博客聚合平台
这,哈哈哈。好主意

给呆哥加了个友联~~
好,我也加上
订阅源也加上了,嘎嘎
咦,真快,一两天就弄好了,导航栏多了一个栏目,看到最后一个换到了第二行去了

额?换行了吗?貌似没有吧。
原来没有,不知道是不是刚刚我在开了F12调试别的网站,宽度搞窄了~
我在开发友链页面的时候就想过做 RSS 集合页。但我不想手动维护 RSS 地址,然而程序判别 RSS 地址不太好实现,除非根据每个人不同的情况,把格式加入穷举来试。但这意味着这个事情要一直更新,违背了我懒人的初衷。
是的,不过这个东西其实是有 api 的,其实接续完善下相关功能,直接根据友联表去动态更新订阅地址。
这个等后面有时间再研究以下。目前的确是不够自动化。
样式比我的好看多了哈,他们开了个头你这技术完全可以定制出些自己的东西
主要是前端不大专业,每次写界面都头大。
有那种现成的采集工具,用Vercel采集数据。
巧了,我今天也抄了一下作业
加好啦~~
姐姐是不是把链接写成了简介
改好啦~~哈哈哈。意外
作业呢?没看着啊
有啊,在友链页面上面有链接。
https://blog.zc.wiki/ylwz.html
嗯嗯,看到了
给我来个呗。
这个只能自己抄啦~~
我之前见有个博友直接写的wp插件,我自己还是分开来订阅rss,主要是没时间折腾这些东西哈哈哈。找到了https://feng.pub/0820235378.html
需要撸好多代码~~
厉害啦!本想逃离微信的朋友圈,又钻进博客的朋友圈….
这个比那个好玩啊 😄
很遗憾地发现,想抄个作业都做不到。
明天也建个页面,先把你们抄作业之前的作业抄了吧
慢慢来,数据处理有bug折腾半天了 还没解决
原来你的好友圈还有不在十年之约的,这就有意思了,发现了新的来源
哈哈哈。啥都有呢~~乱哄哄~~
其实我一直想知道typecho模板怎么弄。
阿峰博客有个自定义插件支持这个功能,不过是wp的。
大概搜了一下找到一个插件,试了下效果不大好。然后就抄了篇作业,虽然有点问题,好在最后都解决了。
我自建了一个php版本的,你们是怎么把二级域名的内容引用到自己页面的啊,我技术菜B完全没理解这个步骤。。。
啊?这个是给对应的服务分配了 一个二级域名,这样调用他下面的服务自然就是二级域名的内容了。
你网站挂啦?
额,我换了下dns,又出错啦???我上电脑看看。。。
你们的样式都好看,就我丑。
https://www.imerduo.com/link
我的是复用的评论的样式表,自己之前写了一个也不好看。
你的那个页面,感觉卡片把内容包起来就好了。改 css 样式真的是挺无奈的,不专业。
晚上继续折腾。
加油~~